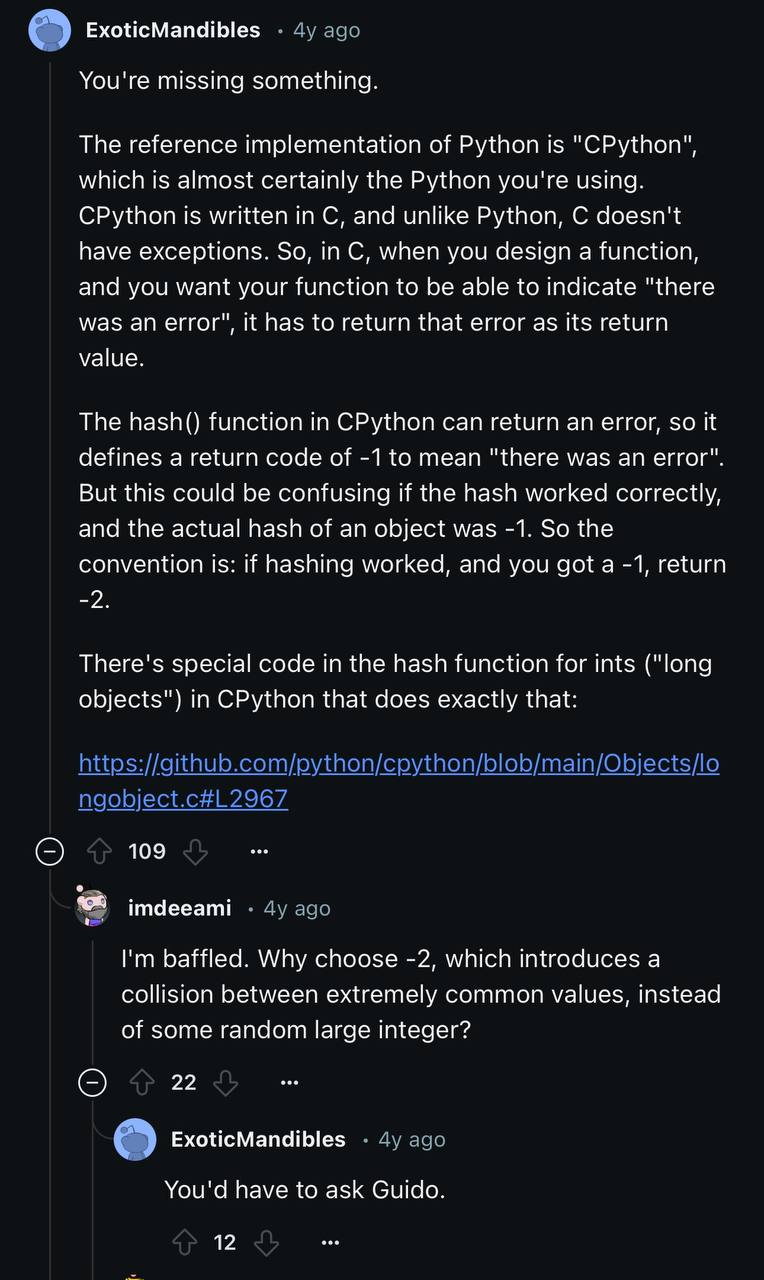
TIL Python use the integer itself as the hash value, except for -1. hash value for -1 is -2.
# For ordinary integers, the hash value is simply the integer itself (unless it's -1).classint:defhash_(self):value=selfifvalue==-1:value==-2returnvalue
Auto-venv
is a Fish shell script that automatically activates and deactivates Python virtual environments when entering/leaving directory that contains virtual environment.
Recently, I added multiple enhancements compare to the upstream version, now it handles edge cases more gracefully:
It safely manages virtual environment inheritance in new shell sessions.
It prevents shell exits during the activation and deactivation processes.
I recently create a Raycast script command to start the
lowfi
command effortlessly, so I can enjoy the lowfi music in no time and control it just using keyboard.
Here is the
gist
, just place the lowfi.sh to the
Raycast Script Directory
. Run it the first time, a wezterm window will be created if lowfi process isn’t running, run it the second time, the wezterm window will be brought to the front.
Problem of using /opt/hombrew/bin/wezterm
While i thought it was a simple task, it tooks me 1 hour to finished it. I encountered a totally unexpected problem: osascript can’t control the wezterm window that running lowfi process.
I installed wezterm using homebrew cask, when launching WezTerm using the Homebrew-installed binary (/opt/homebrew/bin/wezterm), the window was created with a NULL bundleID, which made it impossible for AppleScript/System Events to properly control it. This is because the Homebrew version doesn’t properly register itself with macOS’s window management system.
I was only able to debug this problem thanks to the amazing
aerospace
command
aerospace debug-windows
The solution was to always use the full application path /Applications/WezTerm.app/Contents/MacOS/wezterm for all WezTerm operations, ensuring proper window management integration with macOS.
When launching WezTerm using the full application path (/Applications/WezTerm.app/Contents/MacOS/wezterm), the window is created with the proper bundleID com.github.wez.wezterm. This allows:
System Events to properly identify and control the window
AppleScript to manipulate the window through accessibility actions (AXRaise, AXMain)
To add Mermaid support to Hugo, one key detail not explicitly covered in the
official documentation
is that code fences must be used to enable rendering hooks for code blocks. If code fences are not enabled, the rendering hook has no effect.
Additionally, the condition for including Mermaid.js does not function as expected. Despite trying multiple approaches, I was unable to make it work reliably and ultimately decided to remove the conditional statement entirely.
complete configuration
hugo.toml
[markup][markup.highlight]codeFences=true# enable render code block hooknoClasses=false# tells Hugo to use CSS classes instead of inline styles
OAuth 2.0 is an open authorization framework that allows applications to access resources on behalf of a user, without exposing the user’s credentials. It enables secure access by providing access tokens for API requests, facilitating delegated permissions across services.
Security:
Tokens never exposed to browser
Session cookie only contains session ID
Session cookie typically expires in 24 hours or on browser close
Tokens stored securely on server
User Experience:
Seamless token refresh
No need to re-login when token expires
Single sign-on benefits
Phases
sequenceDiagram
actor U as User
participant C as Client App
participant AS as Auth Server
participant RS as Resource Server
note over U,RS: Phase 1: Authorization Code Request
U->>C: 1. Clicks "Login with Service"
C->>AS: 2. Authorization Request
Note right of C: GET /authorize? client_id=123& redirect_uri=https://app/callback& response_type=code& scope=read_profile& state=xyz789
AS->>U: 3. Shows Login & Consent Page
U->>AS: 4. Logs in & Approves Access
AS->>C: 5. Redirects with Auth Code
Note right of AS: GET /callback? code=AUTH_CODE_123& state=xyz789
note over U,RS: Phase 2: Token Exchange
C->>AS: 6. Token Request
Note right of C: POST /token client_id=123& client_secret=SECRET& grant_type=authorization_code& code=AUTH_CODE_123& redirect_uri=https://app/callback
AS->>AS: 7. Validates Auth Code
AS->>C: 8. Returns Tokens
Note right of AS: { "access_token": "ACCESS_789", "refresh_token": "REFRESH_111", "expires_in": 3600 }
C->>U: 9. Set session cookie
Note right of C: Cookie contains session ID only
note over U,RS: Phase 3: Resource Access
C->>RS: 10. API Request with Access Token
Note right of C: GET /api/resource Authorization: Bearer ACCESS_789
RS->>RS: 11. Validates Token
RS->>C: 12. Returns Protected Resource
note over U,RS: Phase 4: Token Refresh (When Access Token Expires)
C->>AS: 13. Refresh Token Request
Note right of C: POST /token grant_type=refresh_token& refresh_token=REFRESH_111& client_id=123& client_secret=SECRET
AS->>C: 14. Returns New Access Token
Note right of AS: { "access_token": "NEW_ACCESS_999", "expires_in": 3600 }
Token Refreshing Process
sequenceDiagram
participant B as Browser
participant C as Client (Your Server)
participant AS as Auth Server (Google)
Note over B,AS: Initial Login (happens once)
B->>C: 1. User visits site
C->>AS: 2. Redirect to Google login
AS->>B: 3. Login page
B->>AS: 4. User logs in
AS->>C: 5. Auth code
C->>AS: 6. Exchange for tokens
Note right of C: Receives: - Access Token (30 min) - Refresh Token (long-lived) - ID Token (user info)
C->>B: 7. Set session cookie
Note right of C: Cookie contains session ID only
Note over B,AS: Later: Access Token Expired
B->>C: 8. Makes request
C->>C: 9. Checks token found expired
C->>AS: 10. Uses refresh token to get new access token
AS->>C: 11. New access token
C->>B: 12. Serves request
Note right of B: User never sees this process
Token Validation Process
sequenceDiagram
participant B as Browser
participant S as Server
participant R as Redis/DB
participant AS as Auth Server (Google)
Note over B,AS: Scenario 1: Valid Token
B->>S: 1. Request with session_id cookie
S->>R: 2. Lookup user_id by session_id
R->>S: 3. Returns user_id
S->>R: 4. Get tokens for user_id
R->>S: 5. Returns tokens
S->>S: 6. Check token expiration
Note right of S: Token still valid
S->>B: 7. Return requested resource
Note over B,AS: Scenario 2: Expired Token
B->>S: 1. Request with session_id cookie
S->>R: 2. Lookup user_id by session_id
R->>S: 3. Returns user_id
S->>R: 4. Get tokens for user_id
R->>S: 5. Returns tokens
S->>S: 6. Check token expiration
Note right of S: Token expired!
S->>AS: 7. Refresh token request
AS->>S: 8. New access token
S->>R: 9. Store new tokens
S->>B: 10. Return requested resource
Note over B,AS: Scenario 3: Invalid Session
B->>S: 1. Request with invalid session_id
S->>R: 2. Lookup user_id by session_id
R->>S: 3. Returns null
S->>B: 4. Return 401 Unauthorized
token flow
sequenceDiagram
actor U as User
participant B as Browser
participant C as Client App (Your Server)
participant R as Redis/DB
participant AS as Auth Server (Google)
participant RS as Resource Server
note over U,RS: Phase 1: Initial OAuth Login
U->>B: 1. Clicks "Login with Google"
B->>C: 2. Request login
C->>AS: 3. Authorization Request
Note right of C: GET /authorize? client_id=123& redirect_uri=https://app/callback& response_type=code& scope=read_profile& state=xyz789
AS->>B: 4. Shows Login & Consent Page
U->>AS: 5. Logs in & Approves Access
AS->>C: 6. Redirects with Auth Code
Note right of AS: GET /callback? code=AUTH_CODE_123& state=xyz789
note over U,RS: Phase 2: Token Exchange & Session Setup
C->>AS: 7. Exchange auth code for tokens
Note right of C: POST /token client_id=123& client_secret=SECRET& grant_type=authorization_code& code=AUTH_CODE_123
AS->>C: 8. Returns Tokens
Note right of AS: { "access_token": "ACCESS_789", "refresh_token": "REFRESH_111", "expires_in": 3600 }
C->>R: 9. Store tokens
Note right of C: Store in Redis/DB: user_id: user123 access_token: ACCESS_789 refresh_token: REFRESH_111
C->>B: 10. Set session cookie
Note right of B: Cookie contains only: session_id: "sess_xyz"
note over U,RS: Phase 3: Subsequent API Requests
B->>C: 11. Request with session cookie
Note right of B: Cookie: session_id=sess_xyz
C->>R: 12. Look up user_id & tokens
R->>C: 13. Return tokens
C->>RS: 14. API request with access token
Note right of C: Authorization: Bearer ACCESS_789
RS->>C: 15. Return resource
C->>B: 16. Send response to browser
note over U,RS: Phase 4: Token Refresh (Automatic)
B->>C: 17. Later request with session cookie
C->>R: 18. Look up tokens
R->>C: 19. Return tokens (expired)
C->>AS: 20. Refresh token request
Note right of C: POST /token grant_type=refresh_token refresh_token=REFRESH_111
AS->>C: 21. New access token
C->>R: 22. Update stored tokens
Note right of C: Update Redis/DB with new access_token
C->>RS: 23. Retry API request
RS->>C: 24. Return resource
C->>B: 25. Send response
Note right of B: Same session cookie continues to work
-- SQL equivalent using CASE
CASEWHENtotal_spend>=10000THEN'Premium'WHENtotal_spend>=5000THEN'Gold'WHENtotal_spend>=1000THEN'Silver'ELSE'Bronze'ENDasspending_tier
This is similar to accessing previous/next elements in an array iteration.
Recursive CTEs as While Loops
WITHRECURSIVEcountdown(val)AS(SELECT10-- Initial value
UNIONALLSELECTval-1FROMcountdownWHEREval>1-- Loop condition and iteration
)SELECT*FROMcountdown;
HAVING as Filter After Processing: Like applying conditions after a loop completes:
Traditional programming is imperative (you specify HOW to do something)
SQL is declarative (you specify WHAT you want)
The SQL engine optimizes the execution plan
Set-based Operations:
Instead of thinking about individual records, think in sets
Operations like GROUP BY process entire sets of data at once
This often leads to better performance than record-by-record processing
Composition:
CTEs allow you to break complex logic into manageable pieces
Each CTE can build upon previous ones, similar to function composition
This promotes code reusability and maintainability
UNION DISTINCT (or UNION) compares rows based on ALL columns in the corresponding positions, regardless of their names. What matters is:
Column position (order)
Data types (must be compatible)
Values in all columns
Common Pitfalls
data type mismatches
-- Might fail due to type mismatch
SELECTemployee_idFROMemployees-- integer
UNIONSELECTemployee_codeFROMcontractors;-- varchar
column order importance
-- These produce different results
SELECTfirstname,lastnameFROMemployeesUNIONSELECTlastname,firstnameFROMcontractors;
Understanding Common Table Expression (CTE)
What are CTEs?
Common Table Expressions (CTEs) are temporary named result sets that exist only within the scope of a single SQL statement. They’re defined using the WITH clause and can be thought of as “named subqueries” that make complex queries more readable and maintainable.
History
Common Table Expressions (CTEs) are part of the SQL standard
CTEs were first introduced in SQL:1999 (also known as SQL3)
Recursive CTEs were also included in this standard
The syntax using the WITH clause became part of the ANSI/ISO SQL standard
Basic Syntax
WITHcte_nameAS(-- CTE query definition
SELECTcolumn1,column2FROMtable_nameWHEREcondition)-- Main query that uses the CTE
SELECT*FROMcte_name;
Break complex queries into manageable, named components. Easy to maintain and debug
Can reference the same CTE multiple times in a query. Avoid repeating complex subqueries
Recursive calling, can reference themselves to handle hierarchical or graph-like data
WITHRECURSIVEemp_hierarchyAS(-- Base case: top-level employees (no manager)
SELECTemployee_id,name,manager_id,1aslevelFROMemployeesWHEREmanager_idISNULLUNIONALL-- Recursive case: employees with managers
SELECTe.employee_id,e.name,e.manager_id,h.level+1FROMemployeeseINNERJOINemp_hierarchyhONe.manager_id=h.employee_id)SELECTemployee_id,name,level,REPEAT(' ',level-1)||nameasorg_chartFROMemp_hierarchyORDERBYlevel,name;
Advanced Concepts
a) Materialization:
CTEs are typically materialized (computed once and stored in memory)
Can improve performance when referenced multiple times
Some databases optimize by not materializing if referenced only once
b) Scope:
CTEs are only available within the statement where they’re defined
Can’t be referenced across different statements
Can reference earlier CTEs in the same WITH clause
c) Best Practices:
Use meaningful names that describe the data or transformation
Break complex logic into smaller, focused CTEs
Consider performance implications for large datasets
Use comments to explain complex logic
Comparison with other SQL Features
CTEs vs Subqueries:
CTEs are more readable
CTEs can be reused in the same query
CTEs support recursion
CTEs can sometimes perform better due to materialization
CTEs vs Views:
CTEs are temporary and query-scoped
Views are permanent database objects
CTEs can be recursive
Views can be indexed
Analytic Functions (or Window Functions)
Analytic functions are sometimes referred to as analytic window functions or simply window functions
Basic Concept
Window functions perform calculations across a set of table rows that are somehow related to the current row. The key difference from regular aggregate functions is that window functions don’t collapse rows - each row keeps its separate identity while gaining additional computed values.
Think of adding a column that calculate base on a set of rows without collasping rows as GROUP BY does.
function_name()OVER([PARTITIONBYcolumn1,column2,...]-- create group
[ORDERBYcolumn3,column4,...]-- order inside the group
[ROWS/RANGEBETWEEN...AND...]-- widnow frame clause
)
Common Window Functions
Aggregate functions
take all of the values within the window as input and return a single value
MIN()
MAX()
AVG()
SUM()
COUNT()
Navigation functions
Assign a value based on the value in a (usually) different row than the current row.
FIRST_VALUE() (or LAST_VALUE()) - Returns the first (or last) value in the input
LEAD() (and LAG()) - Returns the value on a subsequent (or preceding) row
Numbering functions
ROW_NUMBER() - Returns the order in which rows appear in the input (starting with 1)
RANK() - All rows with the same value in the ordering column receive the same rank value, where the next row receives a rank value which increments by the number of rows with the previous rank value.
Core Concept: Window Frames
Window frames define which rows to include in the window calculation:
-- window frame cluse
ROWSBETWEEN1PRECEDINGANDCURRENTROWROWSBETWEEN1FOLLWINGANDCURRENTROWROWSBETWEENUNBOUNDEDPRECEDINGANDCURRENTROW-- no need to say AND CURRENT ROW, totaly 7 rows, current row is included
ROWSBETWEEN3PRECEDINGAND3FOLLOWING
Core Concept: Understand the OVER Clause - The Window Creator
Think of OVER as opening a “window” through which you look at your data. It’s like saying “calculate this function OVER this specific set of rows.”
Simple example:
-- Without OVER (regular SUM)
SELECTdepartment,SUM(salary)FROMemployeesGROUPBYdepartment;-- With OVER (window function)
SELECTemployee_name,department,salary,SUM(salary)OVER()astotal_salaryFROMemployees;
Key difference:
Without OVER: You get one row per department
With OVER: You keep ALL rows, but each row shows the total salary
name department salary company_total
John IT 60000 250000
Mary IT 70000 250000
Steve HR 55000 250000
Jane HR 65000 250000
Every row shows the company total (250000) while keeping individual salary information.
Core Concept: PARTITION BY - Creating Groups
PARTITION BY divides your data into groups (partitions) for the window function to operate on separately. It’s similar to GROUP BY, but it doesn’t collapse the rows.
Think of it like this:
GROUP BY: Combines rows into one summary row
PARTITION BY: Keeps all rows but performs calculations within each group
name department salary dept_total
John IT 60000 130000 -- Sum of IT salaries
Mary IT 70000 130000 -- Sum of IT salaries
Steve HR 55000 120000 -- Sum of HR salaries
Jane HR 65000 120000 -- Sum of HR salaries
Let’s break down what happened:
PARTITION BY department split the data into two groups: IT and HR
SUM(salary) was calculated separately for each group
Each employee still has their own row, but now shows their department’s total
Visual Explanation
Let’s imagine a more visual example with sales data:
salesperson sale_amount total_sales
Tom 100 700 -- Company total
Tom 150 700 -- Company total
Lisa 200 700 -- Company total
Lisa 250 700 -- Company total
salespersonsale_datesale_amountrunning_totalTom2024-01-01100100-- First day
Tom2024-01-02150250-- First + Second day
Lisa2024-01-01200200-- First day
Lisa2024-01-02250450-- First + Second day
ORDER BY in OVER Clause is often used to creating a running total report
Key Points to Remember:
OVER() without PARTITION BY: Calculates across ALL rows
OVER(PARTITION BY x): Calculates separately for each group of x
You always keep all your original rows
Each row can show both its individual value AND the calculation result
month sales running_total_by_amount running_total_by_month
January 1000 1000 1000
March 1200 2200 2500 -- Jan + Feb
February 1500 3700 4200 -- Jan + Feb + Mar
April 1800 5500 5500 -- All months
month sales previous_month difference
January 1000 NULL NULL
February 1500 1000 500
March 1200 1500 -300
April 1800 1200 600
Calculate with Previous row
prev_break column shows the length of the break (in minutes) that the driver had before each trip started (this corresponds to the time between trip_start_timestamp of the current trip and trip_end_timestamp of the previous trip).
Always specify ORDER BY in window functions when using aggregate functions
Use appropriate indexes for columns in PARTITION BY and ORDER BY
Be careful with frame specifications as they can impact performance
Test with small datasets first
Why window functions were invented
Historical Context:
Before window functions (prior to SQL:2003), developers faced several challenges:
The GROUP BY Dilemma
You either got detail rows OR aggregated results, never both
Had to use complex subqueries or self-joins for analytics
Example problem: “Show each sale AND its percentage of total sales”
Complex Analytics Requirements
Business users needed running totals, rankings, moving averages
Solutions were inefficient and hard to maintain
Required multiple passes over the data
Date function
-- on that day
WHEREDATE(creation_date)='2019-01-01'-- between days
WHEREcreation_date>='2019-01-01'ANDcreation_date<'2019-02-01'--- on that year
WHEREEXTRACT(YEARfromcreation_date)='2019'